Thank you! That was very informing.
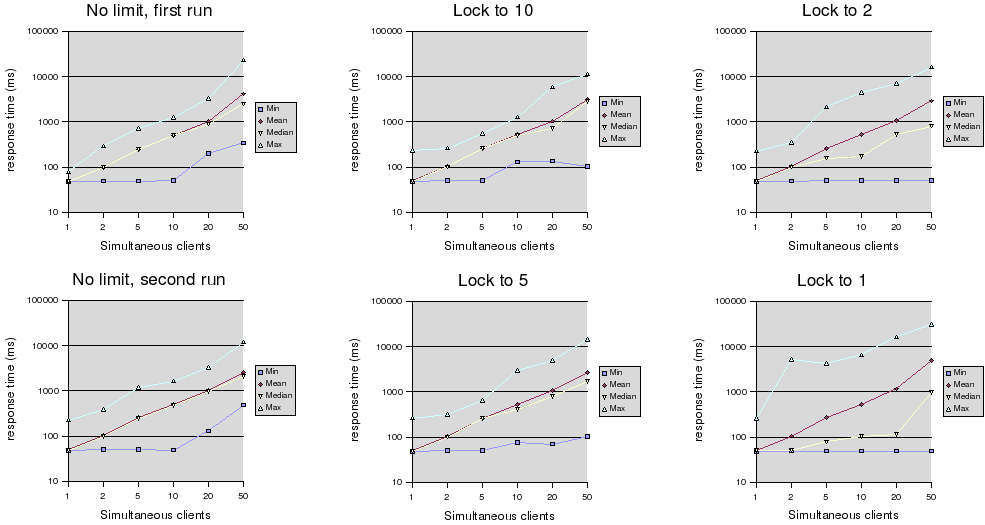
I think the most interesting diagrams are on the top left and the bottom
right, which compares unlimited concurrency to a concurrency level of 1.
It looks indeed as if the average response times with locking are kept
the same by a large increase in maximum time.
However, I believe this phenomena is completely due to the quick-n-dirty
lock implementation. It is not starvation free, and if no locks are
available (as will often be the case with a concurrency level of 1)
every client process will sleep for a second before trying again. This
delay is likely the full cause of the lack of decrease in average
response times.
With a better lock implementation, we should be able to avoid the jump
in median time as shown in the lower right diagram, as well as reduce
the average time significantly, until it approaches the new median.
If this is the case, the average response times with 50 simultaneous
clients could be reduced from about 5000 ms to about 100 ms by using a
better lock. Probably would even a "worse" lock do well, by simply
reducing the retry delay. It would be interesting with a benchmark where
the delay "sleep(1)" has been replaced with a "usleep(100)".
/E23
Brion Vibber
brion-at-pobox.com |wikipedia| wrote:
My very naive quick testing shows that while there is
an improvement in
the median time when locking kicks in, there is no significant
difference in average (mean) response time; the shorter times for some
are paid for by a significant increase in the length and proportion of
slow responses for others.
See benchmark:
http://meta.wikipedia.org/wiki/Lock_response_times
http://meta.wikipedia.org/upload/1/1d/Lock-times.png
Of course, I could be doing something wrong, and this benchmark is very
very naive, making no attempt to work with different types of requests.
{kind=link}